7.1 Business Research in the Age of AI
Research is the cornerstone of informed decision-making. Without research, executives, managers, and colleagues make decisions based on supposition, opinions, and personal preferences, which typically cannot be relied upon if organizations want to thrive in complex, rapidly changing contexts. Qualitative information and quantitative data that reflect current contexts and circumstances along with research based on experience and observation all combine to help decision makers ground their actions on facts. When decisions can be costly and affect employees, clients, and other stakeholders, sound decisions will bolster confidence in the organization’s ability to manage often volatile situations, opportunities, and change. Research is the method by which reliable and valid information is gathered to support decisions.
Data are everywhere. Data are collected during the research process and are used to support, illustrate, and clarify ideas. In persuasive argumentation, data play a critical role in providing the evidence to prove points and strengthen arguments. In measuring performance, data offer reliable metrics, and in marketing, data on customer activity, for example, allow for better personalization and engagement. In the technical and scientific sectors, data can also help with diagnostics and compliance. This data, when gathered, processed, and interpreted ethically, reflect the actual state of affairs because they are obtained from experiences, dynamics, events, phenomena, and the like. For example, you might gather data on various aspects of the usage of AI applications and tools within the supply chain industry, then include these data in an analysis on their effectiveness, accuracy, and impact in a recommendation report.
How do we approach research in business and what forms of information and data do we use? This chapter will help you understand key types of research information and approaches to gathering it.
Business Research Approaches
Given the availability of a variety of search tools and AI applications that can help to accelerate the research process, humans have decisions to make on which approaches they will use to complete the research. For example, AI can save a lot of time in performing secondary research and summarization. Being mindful of various constraints including those relating to purpose, time, subject matter, and available materials and resources will help to narrow the modes that would best be used in a particular research activity. Often, researchers will make use of a variety of approaches through the research process, drawing from any of the following:
Manual: Manual research involves activities that are primarily carried out by humans, with or without the assistance of digital technologies. This type of research could, for example, include interviews and focus groups where information is often collected by hand or recorded, but conducted in a face-to-face context. It could also consist of conducting information searches using online databases, whereby the researcher inputs key words and terms and scans articles in search of useful information. Check out the Seneca Libraries research tools for examples. It can also consist of a simple internet search for information.
Hybrid: Hybrid research is conducted by both humans and AI tools. In such a case, humans would direct the LLM, AI-search tool, or other AI application to follow a specified request or other form of direction, which would then allow the AI tool to complete the search for information. While only some LLMs are reliable enough to be used for research purposes at this time (they are progressively getting better), research dedicated tools tools like Elicit will rapidly narrow the task of finding relevant information. Elicit uses a research question to complete a search and summarizes key information. In a hybrid approach, the tasks are typically distributed between the human and the AI application. For example, you may want to conduct a survey to gather data. You, as the researcher, would develop goals, determine question types, and topic areas to be covered, but then delegate the drafting of the survey questions to a LLM. As discussed in Chapter 2.6 on genAI and workflow, the hybrid method interweaves both human and AI activity in a hybrid workflow.
Automated: Automated research occurs when data is collected automatically with little or no interaction from researchers. Of course, the AI systems must be developed and deployed by humans, but most often these systems function in the background on company websites collecting data without the users even being aware. For example, anytime you visit a commercial website, data is collected on the website usage, time spent, pages visited, and the like. User data is also often collected by way of cookies, which are used to transmit data from the user’s computer to the company’s system. Data is then stored in secure repositories that are accessed by researchers and analysts as needed. See below for more on automated research.
Unless you are a business analyst, marketing analyst, or data analyst, much of the research you will conduct will fall into the manual and hybrid approaches though regardless of your occupation, at some point you will probably be making use of data collected using automated methods.
Working with Research Information and Data
Research is the systematic process of finding out more about something than you already know. Nicholas Walliman, in his handbook Research Methods: The Basics (2011), defines research methods as “the tools and techniques for doing research.” These techniques include collecting, sorting, and analyzing the information and data you find. Regardless of the tools you use to complete your research, placing integrity at the forefront of your activity will result in documents that withstand scrutiny.
Research information can be obtained from a variety of sources which have traditionally been grouped into two broad categories: primary and secondary. In addition, research information can be categorized as qualitative (relying on impressions, feelings, and observations) and quantitative (relying on numbers). The chart below describes the typical sources for these types of information.
Table 7.1.1 Primary versus Secondary Data
| Primary data
Data that have been directly observed, experienced and recorded close to the event. These are data that are gathered by primary researchers through
Note: Primary research done in an academic setting that includes gathering information from human subjects requires strict protocols and will likely require ethics approval. Ask your instructor for guidance and see Chapter 7.4 Human Research Ethics. |
Secondary Data
Comes from sources that store, record, analyze, and interpret primary data. It is critical to evaluate the credibility of these sources. You might find such data in
|
| Quantitative Data
Use numbers to describe information that can be measured quantitatively. These data are used to measure, make comparisons, examine relationships, test hypotheses, explain, predict, or even control. |
Qualitative Data
Use words to record and describe the data collected; often describe people’s feelings, judgments, emotions, customs, and beliefs that can only be expressed in descriptive words, not in numbers. These include “anecdotal data” or personal experiences. |
Research methods are often categorized as quantitative, qualitative, or “mixed methods.” Some projects, like a feasibility project, require the use of a more scientific method of inquiry, observation, quantitative data collection, analysis, and conclusions to test a hypothesis. Other kinds of projects take a more deductive approach and gather both quantitative and qualitative evidence to support a position or recommendation. The research methods you choose will be determined by the goals and scope of your project, and by your intended audience’s expectations.
[/caption]
Knowledge Check
Once you have research information at hand, how do you use it? In most cases, you would want to analyze it to make sense of the data and communicate their relevance in your reports. Specific methodologies that help you to structure the analysis of your data include the following:
- Cost/benefit Analysis: determines how much something will cost vs what measurable benefits it will create.
- Life-cycle Analysis: determines overall sustainability of a product or process, from manufacturing, through lifetime use, to disposal. (You can also perform comparative life-cycle analyses, or specific life cycle stage analysis.)
- Comparative Analysis: compares two or more options to determine which is the “best” solution (given specific problem criteria such as goals, objectives, and constraints).
- Process Analysis: studies each aspect of a process to determine if all parts and steps work efficiently together to create the desired outcome.
- Sustainability Analysis: uses concepts such as the “triple bottom line” or “three pillars of sustainability” to analyze whether a product or process is environmentally, economically, and socially sustainable.
These forms of analyses have evolved into specific report types; see Unit 10 for more information on report writing.
Data in Automated Research
Artificial intelligence has rapidly accelerated the collection of business data because they can be collected automatically around the clock on any website or application accessed by consumers. Such data is gathered to gain insights into consumer behaviors and preferences, website usage, marketing initiatives, and the like. Websites typically collect three types of data, as described by Catherine Cote (2021):
- First-party data: User data that is collected by organizations
- Second-party data: First party user data that is shared by an organization with another
- Third-party data: Rented or sold data offered by organizations that have no affiliation to the receiving organization
Data projects are typically processed in eight phases as described by Tim Stobierski (2021) in the data life cycle as shown in Figure 7.1.1:
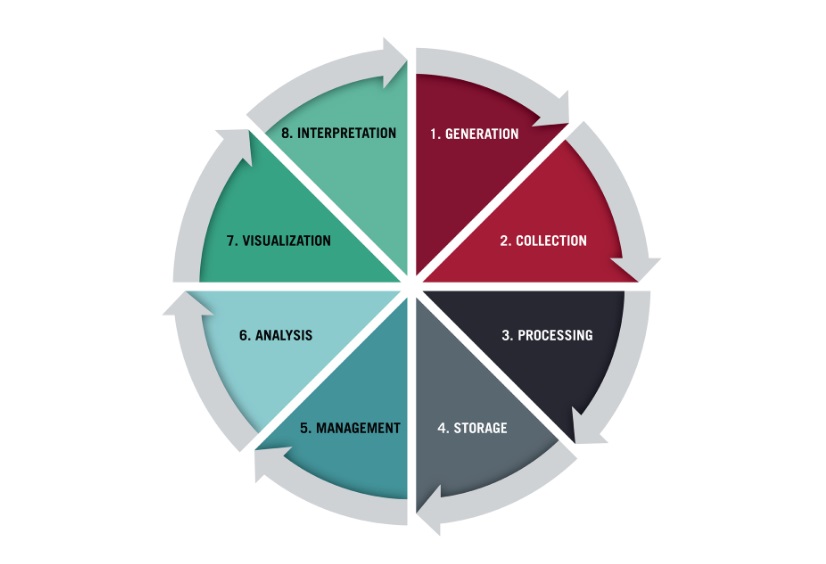
In brief, these eight steps can be described as follows (Stobierski, 2021):
- Generation: Creating data from employee, customer, or electronic types of activity; this activity typically originates from first, second, or third party activity.
- Collection: Gathering data through forms, surveys, interviews, and other methods determined by the researcher.
- Processing: Using various methods to process the collected data. Stobierski (2021) identifies three processing methods:
- Data wrangling: Cleaning and transforming raw data into an accessible format (also known as data cleaning, data munging, or data remediation).
- Data compression: Transforming data into a format enabling more efficient storage.
- Data encryption: Protecting data by encoding them in such a way that hackers cannot access them
- Storage: Storing data in databases or as data sets in secure repositories in the cloud or on servers to be accessed only by researchers and analysts
- Management: Controlling and recording the storage and access of the data at each stage of the data life cycle
- Analysis: Using raw and processed data to gain insights into a particular research question or trend. This use typically involves researchers and analysts using “statistical modelling, algorithms, artificial intelligence, data mining, and machine learning” (Stobierski, 2021).
- Visualization: Using dynamic and static tools to create graphs and other visualizations of the data so that they are easily accessible to readers
- Interpretation: Applying expertise to make meaning and create insights from the data
The Ethical Treatment of Research Data and Information
Regardless of the tools you use to find information to support your ideas, the strength of your reporting on your research findings will always lie with the kind of support included, be it raw or analyzed data or qualitative information, and how you treat that information. In all cases, the way you collect, analyze, and use data must be ethical and consistent with professional standards of validity and integrity. Lapses in integrity can not only lead to poor quality reports in an academic context (poor grades and academic dishonesty penalties), but in the workplace, these lapses can also lead to lawsuits, loss of job, and even criminal charges. Some examples of these lapses include
- fabricating your own data (making it up to suit your purpose),
- ignoring data that disproves or contradicts your ideas,
- misrepresenting someone else’s data or ideas,
- including data that is evidently biased or otherwise skewed,
- using data or ideas from another source without acknowledgment or citation of the source, and/or
- using uncorroborated data and information.
Use of LLMs for research and content creation has complicated our ability to accurately attribute citations. Known for being trained on massive amounts of text, including copyrighted materials, LLM output often includes data and claims that are obviously obtained from sources that are sometimes unidentified (and therefore unusable until they have been corroborated). At this stage in the technology’s development, these sources are often uncited, or they are cited incorrectly. Though LLM developers are actively working on improving citation accuracy, you as a researcher must scrutinize LLM output for unsupported and inaccurate claims and must also carefully corroborate all LLM content that you include in your work to avoid using potentially invalid LLM output that could negatively impact the integrity of your research and your reputation. To corroborate claims, find several verifiable sources that can confirm those claims and use those sources to support the statements you include in your reports. In effect, you are making use of the LLM output as a launch for more specific and narrow research that you then pursue to support your ideas.
Making use of a research approach that is characterized by integrity and the pursuit of facts will allow you to reveal worthwhile information that can be used to support your ideas and create strongly argued points. Following these principles will go far in bolstering your own professional credibility when using LLMs and other AI tools in your research process:
- Accuracy: Since LLM output is known to often lack accuracy and to contain hallucinations, you have an obligation to review all output that you use to ensure its accuracy.
- Corroboration: When LLMs make claims that are unsupported by accurate citations, researchers have the obligation to verify them by analyzing the reports where the information was first published. Corroboration is especially necessary when using LLM output. See Figure 7.1.2 for a guide on checking on the reliability of sources.
- Declaration of AI Use: When traditional citation methods are not applicable, researchers must declare their use of genAI applications, including model, mode, date, and prompts.
- Ethical use: Researchers are obligated to make ethical use of all research materials, including those generated by LLMs and other AI tools. Ethical use involves ensuring accuracy, avoiding bias, inclusivity, citating and declaring sources.
- Privacy: When gathering, storing, and using data, you must ensure that you abide by the Canadian federal and provincial privacy laws. You may want to refer to the Personal Information Protection and Electronic Documents Act (PIPEDA) and Ontario’s Freedom of Information and Protection of Privacy Act (FIPPA)
- Transparency: Be transparent in your research methods and mention that you have made use of AI technologies when you have done so. Be specific as to which tools and methods you have employed. Keep in your records research documentation along with prompts and outputs in case they are requested.
- Validity and reliability: Validity and reliability are qualities that your research information must have in order for it to support your ideas and withstand scrutiny. Validity refers to the “consistency and stability” of the research results, while reliability refers to the “accuracy with which a research measures what it intends to measure” (Salomao, 2023).

Figure 7.1.2 Verifying the credibility of sources (Nylund, 2018)
Your college writing subjects, COM101 and COM111, spent considerable time and effort to give you a sophisticated understanding of how and why to avoid academic integrity offences, as well as the consequences of doing so. If you would like to review this information, see Chapter 8.2: Integrating Source Evidence into Your Writing, and consult Seneca Polytechnic’s Policy on Academic Integrity and Seneca’s Student Resources on Academic Integrity. This textbook unit will provide additional information.
Whatever research methods you use, it is important for you to create a balance between the work you do and the work you delegate to AI. Maintaining human agency in the face of an accelerated and often imperfect technology will ensure that your research meets integrity standards and sustains your credibility and your employer’s reputation.
References
Algonquin College Library. (2020). Plagiarism and you [Video]. Youtube. https://www.youtube.com/watch?v=eYhGPHAnFak&t=34s
Cote, C. (2021). 7 Data Collection Methods in Business Analytics Business Insights Blog. Harvard Business School Online.
Nylund, C. (2018). [Image]. Identifying credible sources. Open Education Alberta, https://openeducationalberta.ca/libraryskills200/chapter/evaluating-resources/Salomao, A. (2023). Reliability vs Validity in Research: Measuring What Matters – Mind the Graph BlogSalomao, A. (2023). Reliability vs Validity in Research: Measuring What Matters – Mind the Graph Blog
Seneca Polytechnic. (n.d.) Academic Integrity Policy. Academic Integrity Policy – Policies – Seneca Polytechnic, Toronto, Canada
Seneca Polytechnic. (n.d.). Student Resources. Academic Integrity at Seneca Polytechnic. Student Resources
Stobierski, T. (2021). 8 Steps in the Data Life Cycle | HBS Online Business Insights Blog.
Walliman, N. (2011). Research methods: The basics. New York: Routledge.
